신경망 학습 - 경사하강법(gradient descent)
신경망을 학습시킨다는 것은 모델이 더 예측을 잘하는 방향으로 가중치를 업데이트해 가는 과정인데, 그렇다면 어떻게(어떤 방향으로, 얼마나) 가중치를 업데이트 해갈 것인지에 대한 방법에 대해서도 생각해보아야할 것이다. 경사하강법은 그 방법에 대한 것이다.
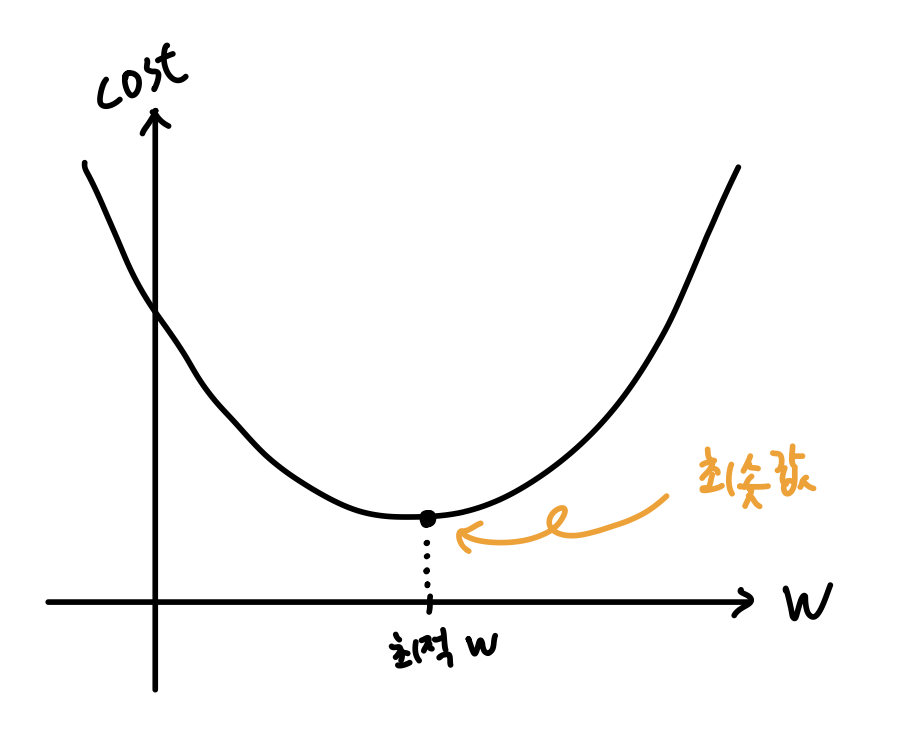
- 비용(예측한 결과가 실제 결과와 얼마나 다른 지를 나타내는 값)을 최소한으로 줄여나가는 것이 학습의 목적이다.
- 즉, 비용 함수를 일반적인 용어로 목적 함수라고 하는 이유라고도 할 수 있겠다.
- 다시 말해, 학습은 최적의 가중치 w(최적값, 최솟값)를 찾아가는 과정.
- 그러나 전체 그래프의 생김새를 알지 못하기 때문에, 기울기를 이용해서 조금씩 이동할 수밖에 없다.

기울기 = 순간 변화량

- 위의 그래프를 보면, 기울기가 음수이면 오른쪽으로 이동하면 되고
- 기울기가 양수이면, 왼쪽으로 이동하면 된다.
- 결국 기울기를 빼는 것이기 때문에, 미분값을 빼는 과정이라고도 표현한다.
- 너무 많이 이동해도 최솟값에서 벗어날 수 있으므로, 기울기에 작은 상수(학습률)를 항상 곱해서 사용한다.
새로운 w
= 원래 w + (기울기 반대방향)
= 원래 w - 기울기
= 원래 w - 학습률 * 기울기
학습률(learning rate)
- 매 업데이트 마다 학습을 얼마나 시킬지 결정하는 값.
- 그렇기에 신경망 학습에 있어서 매우 중요한 요소라고 할 수 있다.
- 이러한 변수를 하이퍼파라미터라고 한다.
- 파라미터보다 더 고차원적인 것.
- 파라미터와 하이퍼파라미터는 명확히 다른 개념이므로 구분할 줄 알아야 한다.
- 파라미터는 모델 내부적으로 결정되는 변수이다. 그 값은 데이터로부터 정해진다.
- 하이퍼파라미터는 사용자가 직접 세팅해 주는 값이다. 정해진 최적의 값이 없다.
머신러닝 - 13. 파라미터(Parameter)와 하이퍼 파라미터(Hyper parameter)
파라미터와 하이퍼 파라미터는 명확히 다른 개념입니다. 하지만 많은 사람들이 두 단어를 혼용해서 쓰고 있습니다. 특히, 하이퍼 파라미터를 파라미터라 칭하는 오류가 많습니다. 파라미터와
bkshin.tistory.com
경사하강법 수식

- :=는 w를 우측의 값으로 업데이트하겠다는 의미
- 알파값은 학습률.
- 알파값에 곱하는 값은 기울기. 이때 쓰이는 것은 편미분.
- 수많은 가중치 w1, w2, … 들로 구성된 식에서 w1이 변할 때 cost가 어떻게 변하는지만 보겠다는 의미이다.
- 모든 가중치 변수들을 한꺼번에 미분해서 기울기를 계산하는 것이 아니라, 각각의 편미분을 통해 기울기를 계산하는 과정을 간소화하기 위함이다.
발생할 수 있는 문제
- 지역 최솟값(local minimum)
- 주변 지역에서는 최소이지만 전체에서는 최소가 아닌 부분을 만나면, 전역 최솟값(global minimum)으로 갈 수 없게되는 것.
- 이를 해결하기 위해서는 기울기만이 아니라 내려가는 가속도를 함께 반영하는 방법을 사용할 수 있음.
- 가속도라는 뜻인 "모멘텀(momentum)"이 그 방법.
- 최근에는 더 다양한 상황에서 학습 실패가 적은 "아담(adam)" 등의 방법이 많이 사용됨.

(확률적) 경사하강법(SGD, Stochastic Gradient Descent), 모멘텀, 아담(adam) 등을 옵티마이저(optimizer)라고 한다.
이는 최적화 알고리즘이다.
이 최적화 알고리즘에 대해서는 다음에 다시 정리하는 시간을 가지는 게 좋을 것 같다.
[비전공자를 위한 딥러닝] 2.5 신경망 (3) - 경사하강법 (문과 버전)
비전공자를 위한 딥러닝, 신경망, 경사하강법, 그레디언트 디센트, 그라디언트 디센트, 가중치 업데이트, 학습률, 러닝레이트, gradient descent, learning rate
www.philgineer.com
경사하강법(gradient descent) - 공돌이의 수학정리노트 (Angelo's Math Notes)
angeloyeo.github.io
'AI > 딥러닝기초' 카테고리의 다른 글
| [딥러닝개론] 순전파와 역전파 (1) | 2023.12.12 |
|---|---|
| [딥러닝개론] 신경망 기초 (2) | 2023.12.05 |
| [딥러닝개론] 선형회귀 (0) | 2023.12.04 |
| [딥러닝 개론] 기본 개념 (2) | 2023.12.04 |


